Реферат Параллельные вычисления. Высшего профессионального образования

Единственный в мире Музей Смайликов
Самая яркая достопримечательность Крыма

Скачать 216.52 Kb.
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ
ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
«САРАТОВСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
ИМЕНИ Н. Г. ЧЕРНЫШЕВСКОГО»
Кафедра математической кибернетики
и компьютерных наук
Параллельные вычисления
магистра 1 курса 171 группы
направления 09.04.01 «Информатика и вычислительная техника»
факультета компьютерных наук и информационных технологий
Белякова Михаила Алексеевича
по предмету «Теория построения отказоустойчивых систем»
Преподаватель Абросимов Михаил Борисович
Поначалу существовал однопрограммный режим работы ЭВМ, но затем в 1964 году фирма IBM выпустила операционную систему — OS 360. Появившаяся у компьютера операционная система стала его полновластным хозяином — распорядителем всех его ресурсов. Теперь программа пользователя могла быть выполнена только под управлением операционной системы. Операционная система позволяла решить две важные задачи — с одной стороны обеспечить необходимый сервис всем программам, одновременно выполняемым на компьютере, с другой — эффективно использовать и распределять существующие ресурсы между программами, претендующими на эти ресурсы. Появление операционных систем привело к переходу от однопрограммного режима работы к мультипрограммному, когда на одном компьютере одновременно выполняются несколько программ.
Создавать параллельные программы стало возможно с появлением в операционных системах механизма порождения потоков или нитей (threads), называемых еще легковесными процессами (light-weightprocess). Где нить — это независимый поток управления, выполняемый в контексте некоторого процесса совместно с другими нитями или процессами. Нити имеют общее адресное пространство, но разные потоки команд. В простейшем случае, процесс состоит из одной нити. Однако, если эти потоки (процессы) совместно используют некоторые ресурсы, к примеру область памяти, то при обращении к этим ресурсам они должны синхронизовать свои действия.
Мультипрограммирование это еще не параллельное программирование, но это шаг в направлении параллельных вычислений.
Мультипрограммирование — параллельное выполнение нескольких программ, оно позволяет уменьшить общее время их выполнения.
Под параллельными вычислениями понимается параллельное выполнение одной и той же программы. Параллельные вычисления позволяют уменьшить время выполнения одной программы. Поэтому имеет место быть следующее определение.
Параллельные вычисления — способ организации компьютерных вычислений, при котором программы разрабатываются как набор взаимодействующих вычислительных процессов, работающих параллельно (одновременно).
Заметим, что наличие у компьютера нескольких процессоров является необходимым условием для мультипрограммирования. Существование операционной системы, организующей взаимную работу процессоров, достаточно для реализации мультипрограммирования. Для параллельных вычислений накладывается дополнительное требование — это требование к самой программе, — программа должна допускать возможность распараллеливания вычислений.
2.Общая информация о параллельных вычислениях
Существуют различные способы реализации параллельных вычислений. Например, каждый вычислительный процесс может быть реализован в виде процесса операционной системы, либо же вычислительные процессы могут представлять собой набор потоков выполнения внутри одного процесса ОС. Параллельные программы могут физически исполняться либо последовательно на единственном процессоре — перемежая по очереди шаги выполнения каждого вычислительного процесса, либо параллельно — выделяя каждому вычислительному процессу один или несколько процессоров (находящихся рядом или распределённых в компьютерную сеть).
Основная сложность при проектировании параллельных программ — обеспечить правильное взаимодействий между различными вычислительными процессами, а также координацию ресурсов, разделяемых между процессами.
3.Классификация многопроцессорных вычислительных систем, используемых для параллельных вычислений
Для реализации параллельных вычислений применяется MIMD (Multiple Instruction, Multiple Data) – система с множественным потоком команд и множественным потоком данных;
Все виды параллельных систем относятся к одной группе MIMD. Дальнейшее разделение типов многопроцессорных систем основывается на способах организации памяти: системы на общей и распределенной памяти.
- мультипроцессорные системы (SMP),
- мультикомпьютерные системы (МРР).
– Мультипроцессорные вычислительные комплексы (общая память) — это компьютеры, обладающие множеством процессоров, работающих на общей памяти. Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число. Вся система работает под управлением единой ОС. В этот класс входит большинство продаваемых сегодня на рынке многоядерных компьютеров.
– Мультикомпьютерные вычислительные комплексы (распределенная память, передача сообщений) — представляют множество узлов, которыми являются компьютеры, соединенных высокоскоростными линиями связи (медные провода, коаксиальный кабель, волоконно-оптический кабель). Каждый компьютер обладает собственной памятью и обменивается сообщениями с другими компьютерами системы для передачи данных.
Здесь может применяться Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс (API) для передачи информации, который позволяет обмениваться сообщениями между процессами, выполняющими одну задачу. В этот класс входят кластеры. Под кластером понимается вычислительный комплекс, рассматриваемый как единое целое, с некоторым выделенным компьютером, играющим роль сервера. Каждый компьютер работает под управлением своей копии операционной системы. Состав и мощность узлов может меняться в рамках одного кластера, давая возможность создавать неоднородные системы.
Поскольку компьютеры, входящие в состав кластера, могут быть обычными компьютерами, то кластеры относительно недороги. Большинство входящих в Top 500 суперкомпьютеров являются кластерами. Самым мощным суперкомпьютером в 2016 году является [Sunway TaihuLight], работающий в национальном суперкомпьютерном центре Китая. Скорость вычислений, производимых им, составляет 93 петафлопс (10 в 15 степени вычислительных операций с плавающей запятой в секунду).
Для кластерных систем в соответствии с сетевым законом Амдаля характеристики коммуникационных сетей имеют принципиальное значение. Коммуникационные сетиимеют две основные характеристики: латентность− время начальной задержки при посылке сообщений и пропускную способность сети, определяющую скорость передачи информации по каналам связи. При выполнении функции передачи данных, прежде чем покинуть процессор, последовательно выполняется набор операций, определяемый особенностями программного обеспечения и аппаратуры.
- Общая память:
- Не тре бу ет ся об мен дан ны ми: дан ные, по ме щён ные в па мять од ним про цес со ром, ав то ма ти че ски ста но вят ся до ступ ны ми дру гим про цес со рам. Со от вет ствен но, си сте ма не долж на тра тить вре мя на пе ре сыл ку дан ных.
- Для та ких си стем про сто пи сать про грам мы: мож но, на при мер, со здать не сколь ко вы чис ли тель ных по то ков, или же снаб дить про грам му спе ци аль ны ми ди рек ти ва ми (на при мер, тех но ло гия OpenMP), ко то рые под ска жут ком пи ля то ру, как рас па рал ле ли вать про грам му. Кро ме то го, воз мож но пол но стью ав то ма ти че ское рас па рал ле ли ва ние про грам мы ком пи ля то ром.
- Ком пакт ность си стем: мо жет быть реа ли зо ва на в ви де не сколь ких про цес со ров на од ной ма те рин ской пла те, и/или в ви де не сколь ких ядер внут ри про цес со ра.
- Про бле ма сов мест но го до сту па к па мя ти: нуж но осто рож но ра бо тать с те ми участ ка ми па мя ти, для ко то рых воз мож но од но вре мен ное вы пол не ние за пи си од ним про цес со ром и дру гой опе ра ции (за пи си или чте ния) дру гим про цес со ром.
- Про бле ма син хрон но сти кэ шей: для уско ре ния до сту па к па мя ти про цес со ры снаб жа ют ся кэ ша ми. Ес ли один про цес сор из ме нил дан ные в опе ра тив ной па мя ти, и эти дан ные про кэ ши ро ва ны дру ги ми про цес со ра ми, то их кэ ши долж ны ав то ма ти че ски об но вить ся. Дан ная про бле ма от сут ству ет в мно го ядер ных про цес со рах, ис поль зую щих об щий кэш.
- Про бле ма мед лен но го об ра ще ния к опе ра тив ной па мя ти и её огра ни чен но го объ ё ма: про цес сор ра бо та ет быст ро, а па мять — мед лен но, по это му да же од но му про цес со ру при хо дит ся ждать за груз ки дан ных из опе ра тив ной па мя ти. Ес ли же про цес со ров не сколь ко, то им при хо дит ся ждать ещё доль ше. Ско рость ра бо ты каж до го про цес со ра с па мя тью ста но вит ся тем мень ше, чем боль шее чис ло про цес со ров име ет ся в си сте ме. Кро ме то го, объ ём па мя ти не мо жет быть сде лан сколь угод но боль шим, так как для это го при дёт ся уве ли чи вать раз ряд ность ши ны па мя ти.
- Про бле ма мас шта би ру е мо сти: очень слож но сде лать по доб ную си сте му с больши́м чис лом про цес со ров, так как очень силь но воз рас та ет сто и мость и па да ет эф фек тив ность ра бо ты из-за опи сан ных вы ше про блем. Прак ти че ски все по доб ные си сте мы име ют ≤ 8 про цес со ров.
- Распределенная память:
1.Использование распределенной памяти упрощает задачу создания мультипроцессорных вычислительных систем.
2.Каждый процесс обладает собственными ресурсами и выполняется в собственном адресном пространстве, таким образом, данные, находящиеся на каждом процессе защищены от неконтролируемого доступа.
3. Универсальность, т.к. алгоритмы с передачей сообщений могут выполняться на большинстве сегодняшних суперкомпьютеров.
4.Легкость отладки.Отладка параллельных программ все еще остается сложной задачей. Однако процесс отладки происходит легче в программах с передачей сообщений. Это связано с тем, что самая распространенная причина ошибок заключается в неконтролируемой перезаписи данных в памяти. Модель с передачей сообщений, явно управляет обращением к памяти, и, тем самым, облегчает локализацию ошибочного чтения или записи в память.
Недостатки организации параллельных вычислений на распределенной памяти:
1.Каждый процессор вычислительной системы может использовать только свою локальную память, поэтому для доступа к данным, располагаемым на других процессорах, необходимо явно выполнять операции передачи сообщений (message passing operations).
2.Проблема эффективного использования распределенной памяти приводят к существенному повышению сложности параллельных вычислений.
5.Модель параллельного выполнения программы
Архитектура комплекса — это лишь одно из требований, необходимых для реализации подлинного параллелизма. Другие два требования связаны с требованиями к операционной системе и к самой программе. Не всякую программу можно распараллелить независимо о того, на каком суперкомпьютерном комплексе она будет выполняться.
Для большего понимания рассмотрим одну из моделей параллельного вычисления.
Итак, у нас имеется программа P, состоящая из n модулей:
 , могут являться входными данными для модуля
, могут являться входными данными для модуля  . Так естественным образом возникает зависимость между модулями, определяющая возможный порядок их выполнения. Множество модулей разобьём на k уровней. К уровню i отнесем те модули, для начала работы которых требуется завершение работы модулей нижних уровней, из которых хотя бы один принадлежит уровню i -1.
. Так естественным образом возникает зависимость между модулями, определяющая возможный порядок их выполнения. Множество модулей разобьём на k уровней. К уровню i отнесем те модули, для начала работы которых требуется завершение работы модулей нижних уровней, из которых хотя бы один принадлежит уровню i -1.

Модуль уровня i с номером k будем обозначать как .
Модули, принадлежащие уровню 1, имеют все необходимые данные, полученные от внешних источников. Они не требуют завершения работы других модулей и в принципе могут выполняться параллельно, будучи запущенными в начальный момент выполнения программы.
Свяжем с программой P ориентированный граф зависимостей модулей. Граф не содержит циклов и отражает разбиение модулей на уровни. Модули являются вершинами графа, а дуги отражают зависимости между модулями. Дуга ведет от модуля к модулю  , если для начала выполнения модуля требуется завершение работы модуля . В узлах графа содержится информация об ожидаемом времени выполнения модуля, где время измеряется в некоторых условных единицах. На рисунке показан пример графа зависимостей:
, если для начала выполнения модуля требуется завершение работы модуля . В узлах графа содержится информация об ожидаемом времени выполнения модуля, где время измеряется в некоторых условных единицах. На рисунке показан пример графа зависимостей:

Рис. 1.1. Пример графа зависимостей
Обозначим через  — время, требуемое для выполнения программы P одним процессором,
— время, требуемое для выполнения программы P одним процессором,  — p процессорами,
— p процессорами, 
Для случая p процессоров можно распределить модули по процессорам, задав для каждого процессора множество модулей, выполняемых этим процессором:
 . После завершения очередного модуля он сразу же переходит к выполнению следующего модуля, если для этого модуля выполнены все зависимости, заданные графом зависимостей. В противном случае процессор ждет окончания работы требуемых модулей. Время завершения последнего модуля в распределении
. После завершения очередного модуля он сразу же переходит к выполнению следующего модуля, если для этого модуля выполнены все зависимости, заданные графом зависимостей. В противном случае процессор ждет окончания работы требуемых модулей. Время завершения последнего модуля в распределении  задает время работы данного процессора. Тот процессор, который последним заканчивает работу и определяет общее время решения задачи
задает время работы данного процессора. Тот процессор, который последним заканчивает работу и определяет общее время решения задачи  для данного расписания.
для данного расписания.
Теперь же рассмотрим 2 ситуации:
А) Модули программы имеют одинаковое время выполнения;
Б) Модули программы имеют разное время выполнения;
Первый случай А)

1)При наличии единственного процессора нетрудно видеть, что
Действительно, один процессор должен выполнить все модули программы, проходя, например, последовательно один уровень за другим.
 модулей уровня i за время
модулей уровня i за время 
Отсюда следует, что общее время работы дается формулой:
 — множество модулей уровня i:
— множество модулей уровня i:
 ( 1.9) ( 1.9) |
Для каждого из этих модулей известно время, требуемое на его выполнение —  — время, требуемое на выполнение всей работы одним процессором:
— время, требуемое на выполнение всей работы одним процессором:
 ( 1.10) ( 1.10) |
2)В случае неограниченного количества процессоров .
Т.е. теперь имеется 2 термина:
- время выполнения модуля
Где под временем окончания работы модуля понимается время выполнения того подграфа который ведет к данному модулю, т.е. этот подграф включает в себя все те модули необходимые для выполнения данного модуля.
Так как подграфы ведущие к i-м вершинам графа могут пересекаться, то и была введена величина окончания работы модуля для того чтобы упростить задачу оценки времени работы программы на данной системе.
Само же время окончания работы модулярассчитывается по следующей формуле:
 ( 1.11) ( 1.11) |
Здесь  — время окончания работы того модуля уровня i-1, который:
— время окончания работы того модуля уровня i-1, который:
- необходим для работы модуля
 ;
; - из всех необходимых модулей завершает свою работу последним.
Тогда время
 ( 1.12)
( 1.12)И теперь становится ясно что время . Проблема составления оптимального расписания в этих условиях относится к NP — полным проблемам, что означает, отсутствие алгоритма полиномиальной сложности, и для решения задачи необходимы переборные алгоритмы. Этим мы не будем заниматься. Займемся тем, что покажем справедливость ранее полученных оценок (8) для в случае, когда время выполнения модулей различно и в графе зависимостей для каждого модуля задано время его работы: Ускорение
Ускорение
Ускорение  определяют как отношение:
определяют как отношение:
Отношение времени выполнения программы одним процессором к времени выполнения программы p процессорами.
Важно правильно интерпретировать это отношение. Числитель и знаменатель, вообще говоря, рассчитываются для двух разных алгоритмов. Когда задача ориентирована на выполнение одним процессором, то можно построить алгоритм, оптимальный для последовательного выполнения. Использование нескольких процессоров, одновременно ведущих вычисления, требует другого алгоритма, предусматривающего распараллеливание. Построение хороших параллельных алгоритмов — это не простая задача. Чаще всего, хороший последовательный алгоритм не является таковым для параллельного выполнения.
Если у нас есть некоторая задача, и речь идет о том, какого ускорения можно добиться при распараллеливании, то в формуле (24) следует сравнивать время наилучшего последовательного алгоритма, для которого достаточно одного процессора, и время наилучшего параллельного алгоритма, который может использовать p имеющихся процессоров.
Максимальное ускорение для задачи задается соотношением:
 Эффективность
Эффективность
Это способность алгоритма использовать все задействованные в выполнении задачи процессоры на 100%. Формула вычисления эффективности:
 Упущенная эффективность
Упущенная эффективность
Введем в рассмотрение меру неиспользованных возможностей — упущенной выгоды — U(n)

Если для компьютера с p ядрами время решения задачи оптимально и сокращается в p раз в сравнении с решением задачи на одноядерном компьютере, то наши потери равны нулю, возможности компьютера полностью используются. Если же задача решается за время — столь же долго, как на одноядерном компьютере, то потери пропорциональны числу неиспользованных ядер.
7.Последовательные части параллельных программах.
- Инициализация и завершение работы;
- Чтение входных данных в запись;
- Синхронизация и критические сети — Пример: пул потоков обрабатывает независимые задания:
- Извлечение заданий из очереди
- Обработка результатов:
- Запись результатов в общую структуру данных;
- Слияние результатов из локальных структур данных;
- Выбор более подходящего алгоритма;
- Увеличение размера решаемой задачи – может оказаться что последовательная часть задачи растет медленнее чем параллельная часть. Пример: умножение матриц.
-сочетание кремния и органических элементов;
Операционная система задумывалась как средство поддержки мультипрограммного режима работы. Первоначально не ставилась цель поддержки параллельных вычислений. Но потоки, работу которых поддерживала операционная система, могут выполняться параллельно. Служебный поток может выполнять чтение данных, в то время как другой поток, выполняемый центральным процессором, может исполнять приложение пользователя. Так что с точки зрения операционной системы параллелизм выполнения потоков был реализован изначально. Появление многопроцессорных комплексов не потребовало принципиальных изменений в архитектуре и идеологии ОС. Дополнительные процессоры естественным образом включались в поддержку параллельной работы потоков.
Для осуществления реальных параллельных вычислений принципиально важным был и тот факт, что потоки могли создаваться и уничтожаться динамически. Один поток во время своей работы мог породить множество дочерних потоков. Это позволяло реализовать настоящий параллелизм — одновременное выполнение несколькими потоками модулей, принадлежащих одному приложению. Многопоточные приложения позволяют реализовать параллельные вычисления.
Создание многопоточных приложений сопряжено с двумя видами трудностей:
На создание и обслуживание потока ОС требуется память и время (создание соответствующих структур данных, поддержка их работы). Создание и уничтожение потока — это достаточно дорогие операции. Поэтому излишнее увлечение многопоточности может привести к потере эффективности работы приложения вместо желаемого ее улучшения. Раздутый административный аппарат — зло, а не благо.
Реализация многопоточного приложения требует усложнения алгоритма. Алгоритм, допускающий распараллеливание, зачастую сложнее последовательного алгоритма, решающего одну и ту же задачу. Но есть приятные исключения. Более того, иногда распараллеливание может быть выполнено автоматически с минимальными затратами для программиста.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- http://www.intuit.ru/studies/courses/10554/1092/lecture/27087
- http://www.studfiles.ru/preview/5282696/page:2/
- https://habrahabr.ru/post/126930/
- http://dic.academic.ru/dic.nsf/ruwiki/1085882
- «Численные методы, параллельные вычисления и информационные технологии» под ред. Вл.В.Воеводина и Е.Е.Тыртышникова
- А.С.Антонов «Введение в параллельные вычисления» (методическое пособие) .
Параллельные вычисления
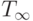 . Когда этот процессор завершит работу, то может оказаться, что появятся готовые к выполнению m модулей уровня j +1 , ожидавших завершения работы
. Когда этот процессор завершит работу, то может оказаться, что появятся готовые к выполнению m модулей уровня j +1 , ожидавших завершения работы  . Только один из этих модулей включается в оптимальное расписание процессора Pr , а остальные будут включены в расписание свободных процессоров, участвующих в работе. Если таковых не окажется, то всегда можно добавить новые процессоры, так что все модули, ожидавшие завершения работы модуля , начнут выполняться одновременно. Отсюда по индукции следует справедливость утверждения для всех уровней. Отсюда же следует, что
. Только один из этих модулей включается в оптимальное расписание процессора Pr , а остальные будут включены в расписание свободных процессоров, участвующих в работе. Если таковых не окажется, то всегда можно добавить новые процессоры, так что все модули, ожидавшие завершения работы модуля , начнут выполняться одновременно. Отсюда по индукции следует справедливость утверждения для всех уровней. Отсюда же следует, что
Покажем теперь, что оптимальное расписание может быть составлено таким образом, чтобы критический путь был назначен одному процессору. Пусть процессор Ps — тот процессор, которому назначен первого уровня, лежащий на критическом пути. Спускаясь по уровням, этому процессору будем назначать модуль, лежащий на критическом пути. Так построенное расписание сохраняет свойство оптимальности, поскольку процессор Ps не простаивает, и ни какой другой процессор не может начать выполнять модули, лежащие на критическом пути, раньше процессора Ps . Заметьте, критический путь, вообще говоря, может быть не единственным.
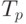
Сложнее получить формулу для вычисления . Проблема составления оптимального расписания в этих условиях относится к NP — полным проблемам, что означает, отсутствие алгоритма полиномиальной сложности, и для решения задачи необходимы переборные алгоритмы. Этим мы не будем заниматься.
Займемся тем, что покажем справедливость ранее полученных оценок (8) для в случае, когда время выполнения модулей различно и в графе зависимостей для каждого модуля задано время его работы:
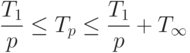 ( 1.12) ( 1.12) |
Дадим вначале графическую интерпретацию. Задание нижней и верхней оценки для  означает, что эта функция ограничена двумя гиперболами. Функция убывающая. В начальной точке при p=1 по определению
означает, что эта функция ограничена двумя гиперболами. Функция убывающая. В начальной точке при p=1 по определению  , так что функция находится в заданном коридоре. Это же справедливо и для конечных точек, для всех p , больших некоторого значения p* , при котором
, так что функция находится в заданном коридоре. Это же справедливо и для конечных точек, для всех p , больших некоторого значения p* , при котором  . Рис. 1.2 иллюстрирует поведение .
. Рис. 1.2 иллюстрирует поведение .

увеличить изображение
Рис. 1.2. Поведение функции Tp(p)
Приведем пример. Рассмотрим двух уровневую систему модулей, граф зависимостей которых показан на Рис. 1.1.
Нетрудно посчитать, что в этом случае:
 равно 15. Критический путь входит в расписание второго процессора. Подключение второго процессора в этой задаче позволяет вдвое уменьшить время выполнения в сравнении со случаем использования только одного процессора. Подключение третьего процессора, хотя и не столь эффективно, но позволит свести время выполнения до минимально возможного результата — Оценка снизу
равно 15. Критический путь входит в расписание второго процессора. Подключение второго процессора в этой задаче позволяет вдвое уменьшить время выполнения в сравнении со случаем использования только одного процессора. Подключение третьего процессора, хотя и не столь эффективно, но позволит свести время выполнения до минимально возможного результата — Оценка снизу
Лемма 1
Для справедлива оценка
 ( 1.13) ( 1.13) |
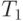
Докажем справедливость оценки. Пусть p процессоров выполняют работу согласно оптимальному расписанию, и ни один из процессоров не простаивает до окончания всей работы. Поскольку в результате все модули будут выполнены, и ни один модуль не будет выполняться дважды, то суммарное время работы всех процессоров равно :
 ( 1.14) ( 1.14) |
Поскольку — это максимальное значение, затраченное одним из процессоров, на выполнение своей работы:
 |
( 1.15) |
Справедливость нижней оценки
| ( 1.16) |
следует из общих свойств суммы компонентов. Максимальный компонент всегда больше или равен среднего арифметического значения суммы.
Если некоторые процессоры могут простаивать, то время может только увеличиваться, что гарантирует выполнения условия (16).
Равенство достигается в единственном случае, когда все компоненты суммы имеют одно и то же значение. Содержательно это означает, что все процессоры одновременно начинают свою работу и одновременно ее заканчивают. В этом случае общее время выполнения работы сокращается в p раз.
Оценка сверху

Пусть работу выполняют p процессоров. Составление расписания означает, что граф зависимостей разбивается на p непересекающихся подграфов. Все модули каждого из подграфов выполняются одним процессором. Подграф с максимальным временем выполнения для данного разбиения будем называть максимально нагруженным подграфом. Оптимальное расписание предполагает такое разбиение, при котором максимально нагруженный подграф выполняется за минимально возможное время. Итак, будем предполагать, что граф зависимостей G разбит на непересекающиеся подграфы :
 ( 1.17) ( 1.17) |
Не снижая общности, будем полагать, что максимально нагруженным подграфом является подграф .
Лемма 2
Для справедлива оценка
 ( 1.18) ( 1.18) |
Доказательство от противного. Покажем, что в этом случае разбиение не является оптимальным и может быть улучшено, что приведет к уменьшению времени .
Итак, предположим, что
 ( 1.19) ( 1.19) |
 ( 1.20) ( 1.20) |
Пусть — минимально нагруженный подграф, тогда время его выполнения не больше среднего времени выполнения, так что имеем:
 ( 1.21) ( 1.21) |
Подграфу можно передать часть работ подграфа , уменьшив суммарное время работы. Действительно, подграф можно представить в виде:
 |
( 1.22) |
Здесь Path это часть пути или некоторый путь, начинающийся на первом уровне, который заведомо меньше критического пути. При передаче его подграфу время выполнения этого подграфа останется меньше времени выполнения подграфа . Общее время выполнения работ при этом уменьшится. Следовательно, пришли к противоречию с утверждением об оптимальности расписания, что доказывает справедливость соотношения:
 ( 1.23) ( 1.23) |
В заключение дадим некоторые практические рекомендации, следующие из полученных оценок. Выигрыш, который можно получить, используя дополнительные процессоры, зависит от разницы между общим временем выполнения всех модулей программы — и временем выполнения критического пути в графе зависимостей — — это время выполнения всех модулей, а и равно при любом числе процессоров, так что привлекать дополнительные процессоры в этом случае бессмысленно.
Для строго последовательной программы, когда i -й модуль зависит от модуля i -1, все три характеристики будут совпадать. Для строго последовательной программы дополнительные процессоры не позволяют уменьшить время выполнения программы в сравнении со временем выполнения этой же программы одним процессором. Так, например, задача о «Ханойской башне» на суперкомпьютере с сотнями тысяч процессоров будет решаться столь же долго, как и на компьютере с одним процессором. Это вытекает из сути задачи, — перенос следующего кольца требует завершение переноса предыдущего кольца, — параллельно эту работу выполнять нельзя.
Источник https://topuch.com/visshego-professionalenogo-obrazovaniya-v7/index.html
Источник https://intuit.ru/studies/courses/10554/1092/lecture/27087?page=3
Источник